BEFORE LEARNING HOW TO WRITE a web application, you need to understand a bit about how web browsers work, and how web applications interact with users.
A web browser, at its core, is a fairly simple application. Basically, web browsers can
Request files from web servers.
The World-Wide Web is composed of thousands of web servers connected to the Internet. Each web server contains lots of different kinds of files that web browsers can request: HTML pages, image files, audio files, and other resources. When you click a link on a web page, the web browser sends a request to the web server, which transmits the requested file back to the browser.
Process the downloaded files appropriately.
Once the web browser has downloaded the requested file, it needs to do something with it. Web browsers know how to render an HTML document, show images, play audio files, and so on. If the web browser doesn't know what to do with a file, it usually prompts the user to save the file, so the user can do something with it.
Let's take a specific example. Start up your browser and type in the following URL:
http://www.cs.bju.edu/cps/courses/cps110/textbook.html
![[Note]](images/note.gif) | Note |
|---|---|
A URL ("Uniform Resource Locator") is the address of a document on the World-Wide Web. It has three sections: the protocol (ex. http:), the server where the document is located (ex. www.cs.bju.edu), and the path to the requested resource on the server (ex. /cps/courses/cps110/textbook.html). | |
When you press Enter, here's what happens:
The browser opens a network connection to the web server named www.cs.bju.edu
The browser requests the file /cps/courses/cps110/textbook.html from the web server
The web server transmits the HTML file back to the browser
The browser renders the HTML document

If you want to see the file transmitted by the web server to the browser, right-click in the browser window and choose View Source. The browser shows you the file it downloaded from the web server.
Most of the time, when your browser requests a file from a web server, the server simply transmits the contents of the file back to the browser. But sometimes, the "file" your browser requests isn't really a file at all.
Try typing the following URL into your browser:
http://www.google.com/search?q=Microsoft
You'll get back a page of search results about Microsoft from the Google search engine (at least, you will unless Google has changed how it performs searches since the time I wrote this chapter). How did this happen?
Well, your browser did what it always does when you type in a URL:
The browser opened a network connection to the web server named www.google.com
The browser requested the "file" named /search?q=Microsoft from the web server
What the web server did at this point is different than the example above. There's no "file" named "/search?q=Microsoft" on the Google web server. Instead, the web server ran a web application to search through Google's massive database of websites for pages that mention "Microsoft". The web application dynamically generated an HTML document containing the search results, and the web server transmitted that document back to the browser.
The browser rendered the HTML document
As far as your browser is concerned, there is no difference between requesting a "static" HTML file from a web server, and requesting a dynamically generated HTML file. It's up to the web server to examine the request submitted by the web browser to determine whether it should serve up a regular document, or run a web application to generate a response.
Anytime you're browsing the web, and you notice that the URL of the page you're viewing has a question mark (?), you can be fairly certain that the page was generated "on the fly" by a web application on a web server. By the way, the portion of the URL that comes after the ? is called the "query string," and contains input for the web application. Try changing the query string by substituting "Firefox" for "Microsoft" to see what I mean.
In summary, a (server-side) web application is a program that is run by a web server to produce output in response to an incoming request from a web browser.
Perhaps you're thinking, "I don't usually perform searches by typing in URL's -- I fill out a search form." True -- if web applications forced users to interact with them by entering query strings, the World-Wide Web would be a much less popular place.
So go ahead -- bring up the Google home page (I'll wait):
Now, type in your query. When I type in "Microsoft" and click Search, here is what I see:
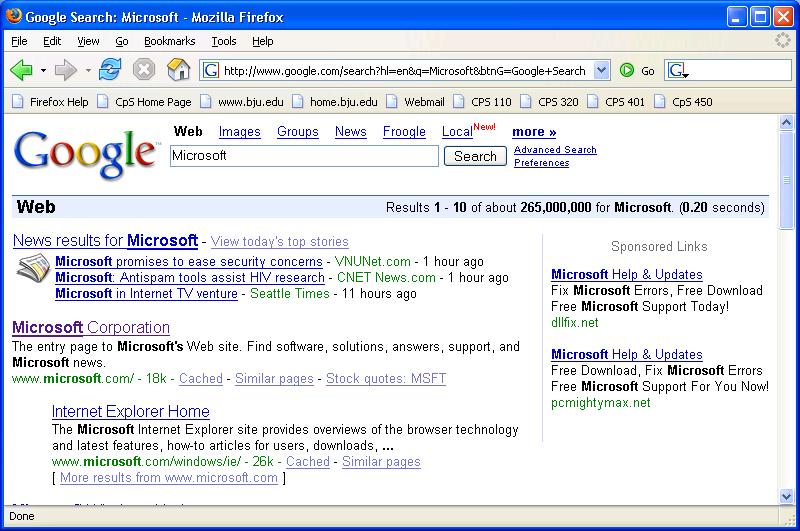
Now, take a good look at the URL in the title bar -- notice the query string? It's a bit more complicated than the one I had you create by hand earlier. But you can probably pick out the "q=Microsoft" if you look closely. How did all of that get there? Well, when you clicked Search, the browser took the information you typed into the form, packaged it up into a query string, and transmitted it to the Google web server. You see, when you fill out a form on a web page and click Submit, the browser uses the form data to construct a URL, and then sends a normal request to the web server.
Even if you're a novice at writing HTML pages, it's not hard to learn to create HTML forms. Take a look at this simplified version of the Google home page:
Figure 8.3. googleform.html
<html>
<head>
<title>Google</title>
</head>
<body>
<div align="center">
<img src="http://www.google.com/images/logo.gif"><br><br>
<form action="http://www.google.com/search">
Enter your search words: <input type="text" name="q"><br>
<input type="submit" name="btnG" value="Google Search">
</form>
</div>
</body>
</html>Focus on the highlighted region of this example, which defines the form. Later, I will go into more detail about how to create HTML forms, but for now, here's a quick overview:
The form is the region of the page in between the <form> and </form> tags.
The form can contain a mixture of text, regular HTML formatting tags, and form <input> tags
Each <input> tag has a type and a name attribute. The type attribute specifies what kind of input area it is ("text" for a text box, "submit" for submit button, etc.). The name attribute specifies a name for the input area.
When the user fills out the form and clicks the submit button, the browser constructs a URL by taking the form's action attribute (http://www.google.com/search), appending a ?, and constructing the query string using the names of the form input areas, together with the data entered by the user.
Try it out! Using Notepad, type in this example, and save as googleform.html. Open it in your browser; you should see something like this:
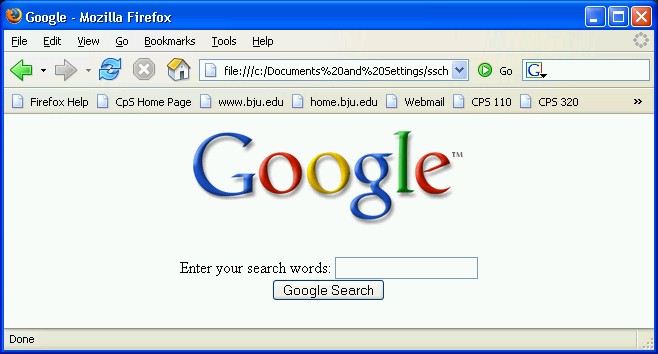
Fill out the form, and, if Google still works as it did when this chapter was written, you should see search results appear in your browser.