In the last chapter, we defined a Point class this way:
class Point {
int x, y;
}Using this class, we created simple Point objects like this:
Point here = new Point();
These simple objects are useful because they allow us to treat a group of related variables as a unit. But they aren't true objects. Here's a definition for object:
An object is an entity that contains both data and methods that operate on that data.
By this definition, our "simple objects" aren't objects at all. They are really just structured variables. In this section, you will learn how to create true objects -- "smart" objects that contain methods as well as data.
By the way, the concept of packaging data together with methods that use that data is called encapsulation, and is one of the key ideas of Object-Oriented Programming.
Let's add a method to the Point class, like this:
class Point {
int x, y;
public void Show() {
Console.WriteLine("Point: (" + x + ", " + y + ")");
}
}The Point class contains two instance variables (x and y) and one method, Show(). Notice that the Show() method is not marked static. That is because Show() is not a class method; it is an instance method. An instance method is a method that uses data in an object. In practical terms, this means that, to invoke Show(), we must first create a Point object, and then invoke the method on the object, like this:
Point here = new Point(); here.x = 5; here.y = 10; here.Show();
What do you think is output by the show() method? If you said
Point: (5, 10)
you are correct! The Show() method uses the values in the instance variables of the object here.
This simple example illustrates an important idea about objects: they do not merely contain data, but they also contain methods that use that data.
Let's look at another example code fragment using the Point class:
Point here = new Point(); here.x = 5; here.y = 10; Point there = new Point(); there.x = 20; there.y = 30; here.Show(); there.Show();
In this example, two Point objects named here and there are created. When here.Show() is called, the code inside show() uses the values of x and y in the here object, so the following appears:
Point: (5, 10)
When there.Show() is called, the values of x and y in the there object are used, resulting in the following output:
Point: (20, 30)
This illustrates another important idea about objects: when an object method is invoked, it uses the data inside the instance on which the method was invoked. Invoking the same method (Show) on two different instances (here and there) produces different results, because each object has its own values in its instance variables.
The term state refers to the values of the variables inside a particular object instance. So, you could say that the results of invoking an object method depend on the object's state. This is not a new concept; you've been taking advantage of this idea since you started using string methods. Consider this code fragment:
String name1 = "Frank", name2 = "Jill"; string name1upper = name1.ToUpper(); string name2upper = name2.ToUpper();
Invoking the ToUpper() method on two different objects (name1 and name2) yields different results, because the method uses the object's state (in this example, the state is the text in the string) to produce its result.
Now, let me try to explain why the Show() method is not marked static. C# imposes the following limitation on static methods:
Static methods are not permitted to use instance variables.
That means that, if you marked Show() static, the C# compiler would report an error, because Show() uses the values of the instance variables x and y to display its output. This error makes sense when you think about how you would invoke the Show method if it were static:
Point.Show(); // invoking a static show method
The Show() method needs to know the values of x and y so it can display them, but which x and y variables would it use? It gets them from the object you used to invoke the method, but when you invoke the method with the class name before the dot, there isn't an object for it to get the data from. Since this situation creates a problem, C# prevents static methods from accessing instance variables.
The error message you get if you mistakenly mark Show() static looks like this:
An object reference is required for the nonstatic field, method, or property 'Point.x'
In the heat of programming, you might be tempted to mark x and y static to get rid of the compile error. That would eliminate the compile error, but it would be solving it in entirely the wrong way. You would end up with something like this:
// NOTE: THIS CLASS CAN'T BE USED TO CREATE OBJECTS
class BadPoint {
static int x, y;
static void Show() {
Console.WriteLine("Point: (" + x + ", " + y + ")");
}
}Adding the word static changes the picture entirely. This class defines a group of variables and methods, but you wouldn't use it to create objects. The word static means that you access all the members by writing the class name before the dot, like this:
BadPoint.x = 5; BadPoint.y = 10; BadPoint.Show();
Although this works, it's very limiting -- remember from the discussion in the last chapter that you can only have one BadPoint, you can't pass it as a parameter or return it from a method, etc. From the discussion in the last chapter, you should be able to understand why this is not appropriate.
This is probably a good time to review an important point I made in chapter 4. Classes serve two purposes in C#. One purpose is to group together related variables and methods -- the Console and Convert classes are examples of this. In these classes, all of the methods and variables are marked static. You don't create Console and Convert objects from these classes, because they don't contain any instance variables.
The other purpose for classes in C# is to define objects. Most C# classes, including the String and Point class, fall into this category. These classes may have a few static members ("class methods"), but most of their members are usually non-static ("object methods"), meaning you must have an object to use the method.
If you had difficulty following the reasoning in this section, just remember this:
![[Note]](images/note.gif) | Note |
|---|---|
Never mark an object method static. | |
When an object is first created, its instance variables take on default values. Often, it's convenient to be able to have greater control over how the instance variables are initialized. For example, it would be nice if the programmer could specify the initial values of the instance variables when he creates the object, like this:
Point here = new Point(3, 10);
We can do this if we add a special method called a constructor to the Point class. A constructor is a method that has the same name as the class, and no return type. Constructors are invoked when the class is instantiated with the new operator, and their sole purpose is to initialize instance variables.
Here's an example of a Point class with a constructor method:
class Point {
int x, y;
public Point(int initX, int initY) {
x = initX;
y = initY;
}
... other methods ...
}The constructor method is shown in bold. Notice that it has no return type (not even void). Now, a programmer can create a Point object like this:
Point here = new Point(3, 10);
When a Point object is created , the 3 and the 10 are passed to the constructor parameters initX and initY, respectively, which are used to initialize the instance variables.
Once you define a constructor method with parameters, you can no longer instantiate the class without parameters, like this:
Point there = new Point(); // NOT PERMITTED
There is a solution to this problem. You can define several constructors in a class, as long as they have different interfaces. For example, you could define a Point class with two constructors, like this:
class Point {
int x, y;
public Point() {
x = 0;
y = 0;
}
public Point(int initX, int initY) {
x = initX;
y = initY;
}
... other methods ...
}Now, we can create a Point object either way.
Here is a useful class that extracts data from a string.
class SimpleStringTokenizer {
string data;
char separator;
int curIndex;
public SimpleStringTokenizer(String initData) {
data = initData;
separator = ' ';
curIndex = 0;
}
public SimpleStringTokenizer(string initData, char initSeparator) {
data = initData;
separator = initSeparator;
curIndex = 0;
}
public bool HasMoreTokens() {
while (curIndex < data.Length &&
data[curIndex] == separator) {
curIndex++;
}
return (curIndex < data.Length);
}
public string NextToken() {
if (HasMoreTokens()) {
int startPos = curIndex;
while (curIndex < data.Length &&
data[curIndex] != separator) {
curIndex++;
}
string token = data.Substring(startPos, curIndex-startPos);
curIndex++; // move past separator
return token;
} else {
throw new Exception("No more tokens");
}
}
}The basic idea is that we have to keep track of three pieces of information:
The String being tokenized (data)
The token separator character (separator)
The current position in the String (curIndex)
Look at SimpleStringTokenizer's two constructors. We can specify a separator character if we want to, or not. If we don't specify a separator character, a space is used as the default.
Here's a simple program that demonstrates use of the SimpleStringTokenizer:
class TokenTest {
static void Main() {
SimpleStringTokenizer tok = new SimpleStringTokenizer("Eat Chicken");
while (tok.HasMoreTokens()) {
String word = tok.NextToken();
Console.WriteLine(word);
}
}
}Let's walk through the program and see how it works. In fact, I encourage you to use a debugger to step through the program as you read this.
The following statement invokes the first constructor, since only one parameter is supplied:
SimpleStringTokenizer tok = new SimpleStringTokenizer("Eat Chicken");After tok is instantiated, here's its state:
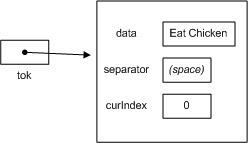
Now, consider the following loop:
while (tok.HasMoreTokens()) {
String word = tok.NextToken();
Console.WriteLine(word);
}When tok.HasMoreTokens() is called the first time, it returns true. Inside the loop, tok.NextToken() extracts the first token ("Eat") and changes curIndex to point to the beginning of the next token. Here's what tok looks like after tok.NextToken() is called:
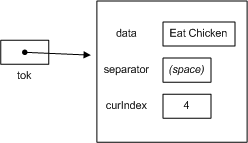
Back at the top of the loop, tok.HasMoreTokens() again returns true, since curIndex is still "in bounds." Here's what tok looks like after tok.NextToken() returns "Chicken":
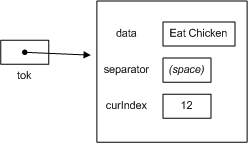
Back at the top of the loop, tok.HasMoreTokens() now returns false, since curIndex is now out of bounds.
As you can see, the code is a bit complicated. But I want you to get the big picture here:
From the perspective of the programmer using the SimpleStringTokenizer to tokenize a string, life is pretty simple. Instantiate a SimpleStringTokenizer, and call NextToken() until HasMoreTokens() returns false.
The SimpleStringTokenizer contains all of the state necessary to keep track of what string it is tokenizing, what separator character it is using, and how much of the String has been tokenized. The methods in SimpleStringTokenizer use/update the data in the instance variables to do their work.
If needed, a programmer could create several SimpleStringTokenizer objects and use them simultaneously to tokenize different strings using different separator characters. This is something that could not happen if SimpleStringTokenizer were a class with static variables and methods; if we had done that, then we could tokenize only one String at a time.
From this example, you can begin to see the true power of object-oriented programming. It's abstraction at work. Complicated details are hidden away inside the SimpleStringTokenizer methods, but the programmer using the object doesn't have to be concerned with how it works. The SimpleStringTokenizer is a very smart object, indeed.